

<컴파일러 최적화>
1. 스레드의 전역 변수 접근
아래의 코드를 보면 ThreadMain은 누군가가 전역변수 _stop을 true로 바꾸지 않으면 계속 무한 루프를 돌아서 프로세스가 끝나지 않는 함수이다.
1) Main 함수에서 Task를 이용하여 ThreadMain을 실행하는 스레드를 생상한다.(ThreadPool 중 하나의 Thread에게 ThreadMain을 실행하도록 함)
2) 후에 Main 함수(Main Thread)를 1초 동안 잠들게 한다. (Task 스레드가 실행하도록) 깨어나면 메인 스레드가 _stop을 true로 바꾼다. 이때 Task 스레드가 while문에서 빠져나올 수 있다
3) t.Wait()(Thread에서 Join 함수와 같은 역할)을 통해 Task t가 종료되기를 기다린 후 메인 함수 종료하도록
4) 아래의 사진과 같이 원하던대로 제대로 실행된다.
namespace SeverCore
{
class Program
{
// 전역변수는 모든 스레드가 공통으로 접근할 수 있음
static bool _stop = false;
static void ThreadMain()
{
Console.WriteLine("쓰레드 시작!");
while (_stop == false)
{
// 누군가가 stop 신호를 해주기를 기다린다.
}
Console.WriteLine("쓰레드 종료!");
}
static void Main(string[] args)
{
Task t = new Task(ThreadMain);
t.Start(); // ThreadPool에 있던 thread하나에게 ThreadMain함수 실행하도록함
Thread.Sleep(1000); // 메인 스레드 1초동안 잠들었다가 깨어남
_stop = true;
Console.WriteLine("Stop 호출");
Console.WriteLine("종료 대기 중");
t.Wait(); // Thread의 Join 개념
Console.WriteLine("종료 성공!");
}
}
}
2. 위의 코드를 지금까지 해왔던 Debug 모드가 아닌 Release 모드로 실행시키면 위에와는 다른 결과가 나옴
1) Release 모드에서 While(_stop == false)에 breakpoint를 잡고 디버깅을 한 후, 디버그 -> 창 -> 디스어셈블리를 클릭하면
가장 컴퓨터와 가까운 언어인 디스어셈블리어가 나타난다.
2) Release 모드에서 최적화가 되면서 컴파일러가 ThreadMain의 함수만을 보고 최적화
함수 내에 _stop을 바꿔주는 것이 없기 때문에 While문을 아래와 같이 최적화를 한다.
if(_stop == flase){
while(true){
}
}
3) 최적화를 하지 않도록 volatile을 이용
아래와 같이 volatile을 붙여주면 최적화를 하지 않기 때문에 이렇게 한 후 실행하면 다시 정상적으로 나온다.
하지만, C#에서 사용하지않기를 권장함
volatile static bool _stop = false;=> 코드 최적화 때문에 Release 모드에서는 다양한 버그가 발생할 수 있다.
<캐시 이론>
1. CPU 코어 내부에 ALU(연산 장치)가 있고 기억 장치인 캐시 장치가 있다. 실제 데이터가 변경됐을 때, 매번 메인 메모리(RAM)에 저장을 하는 것은 비용이 많이 든다.
-> 우선, 메모리를 캐시에 저장한 후에 일정 시간이 지날 때, 한번에 저장 메인 메모리(RAM)에 저장하도록 한다.
-> 캐시(레지스터 -> L1 캐시 -> L2 캐시)
2. 캐시 철학
1) Temporal locality: 시간 측면에서 봤을 때, 가장 최근에 사용된 메모리가 재사용될 확률이 높다.
2) Spacial locality: 공간적 측면에서 봤을 때, 방금 접근한 메모리 주변의 메모리가 또 재사용될 것이다.
3. 멀티쓰레드 환경에서 각각 스레드가 가지고 있는 데이터가 달라져 문제가 된다.
멀티 코어 환경에서 코어 각각이 캐시 장치가 존재함.
하나의 코어가 어떤 메모리에 저장될 데이터를 가지고 있음에도 메인 메모리에 저장되지 않는 한 다른 코어는 해당 데이터를 볼 수 없다.
4. 캐시 실습
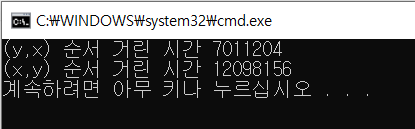
아래의 코드를 보면 2차원 배열에서 위의 블록 안에서는 for 문이 2차원 배열을 접근할 때, 하나에 행에 모든 열을 접근한 후 그 다음 행을 접근하는 식으로 한다.
다음과 2차원 배열이 있을때 메모리 상에서의 주소가 열에 인접해있다. 캐시 메모리의 공간적 특성이 반영
[] [] [] [] []
1 2 3 4 5
[] [] [] [] []
6 7 8 9 10
따라서, 아래의 블록처럼 for문으로 행마다 접근하는 것보다 위의 블록의 for문처럼 열로 접근하는 것이 보다 빠르다.
class Program
{
static void Main(string[] args)
{
int[,] arr = new int[10000, 10000];
{
long now = DateTime.Now.Ticks;
for (int y = 0; y < 10000; y++)
for (int x = 0; x < 10000; x++)
arr[y, x] = 1;
long end = DateTime.Now.Ticks;
Console.WriteLine($"(y,x) 순서 거린 시간 {end - now}");
}
{
long now = DateTime.Now.Ticks;
for (int y = 0; y < 10000; y++)
for (int x = 0; x < 10000; x++)
arr[x, y] = 1;
long end = DateTime.Now.Ticks;
Console.WriteLine($"(x,y) 순서 거린 시간 {end - now}");
}
}
}
<메모리 배리어>
1. 하드웨어 최적화 실습
아래와 같이 코드를 짠 후, r1과 r2가 둘다 0이 되는 순간에 빠져나오도록 했을 때, 실제로 어떤 경우의 수에서도 r1과 r2가 0이 될 수 없지만 빠져나오는 것을 확인할 수 있다.
=> voltaile을 통해 컴파일러 최적화로 인한 것인지 확인해봐도 아님
=> 문제는 하드웨어도 최적화를 함
: 명령어가 서로 아무런 연관성이 없다고 판단하면 명령어의 순서를 최적화에 맞춰서 바꿔버린다
ex) y = 1과 r1 = x는 아무런 연관성이 없기 때문에 (하드웨어가 보기에, 멀티 스레드를 고려하지않는) 두 명령어의 순서를 바꿀 수 있다.
namespace SeverCore
{
class Program
{
static int x = 0;
static int y = 0;
static int r1 = 0;
static int r2 = 0;
static void Thread_1()
{
y = 1; // Store y
r1 = x; // Load x
}
static void Thread_2()
{
x = 1; // Store x
r2 = y; // Load y
}
static void Main(string[] args)
{
int count = 0;
while (true)
{
count++;
x = y = r1 = r2 = 0;
Task t1 = new Task(Thread_1);
Task t2 = new Task(Thread_2);
t1.Start();
t2.Start();
Task.WaitAll(t1, t2);
if (r1 == 0 && r2 == 0)
break;
}
Console.WriteLine($"{count}번 만에 빠져나옴!");
}
}
}2. 메모리 베리어
1) 코드 재배치 억제
명령어의 순서를 바꿀 수 없도록 하나의 막을 세운다는 느낌
a) Full Memory Barrier (ASM MFENCE, C# Thread.MemoryBarrier) : Store/Load 둘다 막는다.
b) Store Momory Barrier (ASM SFENCE): Store만 막는다.
c) Load Memory Barrier (ASM LFENCE): Load만 막는다
C#에서는 Thread.MemoryBarrier()를 통해 코드 재배치를 억제할 수 있다.
다음 코드로 실행하며는 while의 무한 루프를 도는 것을 확인할 수 있다.
static void Thread_1()
{
y = 1; // Store y
Thread.MemoryBarrier();
r1 = x; // Load x
}
static void Thread_2()
{
x = 1; // Store x
Thread.MemoryBarrier();
r2 = y; // Load y
}2) 가시성
스레드가 수정하고자 하는 데이터의 내용을 다른 스레드도 볼 수 있는가? -> 가시성
스레드가 메인 메모리에 저장을 하면, 다른 스레드가 해당 메모리의 데이터를 가져올때 가장 최근에 동기화된 메모리를 가져오도록 함
Memory Barrier가 간접적으로 이러한 가시성의 역할을 한다.
y = 1 명령어 다음에 Memory Barrier를 하면 1이 새롭게 y에 Store된다는 것(메인 메모리)을 의미하고, 이후에 r1 = x 명령어는 가장 최근에 동기화된 메인 메모리에서 데이터를 가져올 수 있음
static void Thread_1()
{
y = 1; // Store y
Thread.MemoryBarrier();
r1 = x; // Load x
}
'Development > 게임 서버' 카테고리의 다른 글
| [Part 4 게임 서버] 멀티쓰레드 프로그래밍 5(Lock 구현 이론 ~ AutoResetEvent) (0) | 2022.01.10 |
|---|---|
| [Part 4 게임 서버] 멀티쓰레드 프로그래밍 4(Lock 기초, DeadLock) (0) | 2022.01.07 |
| [Part 4 게임 서버] 멀티쓰레드 프로그래밍 3 (Interlocked) (0) | 2022.01.07 |
| [Part 4 - 게임 서버] 멀티쓰레드 프로그래밍1(개론과 스레드 생성) (0) | 2022.01.06 |
| [Part 4 게임 서버 - 개론] (0) | 2022.01.04 |